- BFS의 개념
- BFS에 대한 간단한 코드 설명
- BFS의 장단점
- LeetCode 예시 문제 및 참고 코드
BFS ( Breadth First Search )는 너비 우선 탐색이라 불리는 알고리즘이다.
해당 알고리즘은 보통 DFS ( Depth First Search)와 많이 비교 된다.
두 알고리즘은 모두 그래프를 탐색하는데 많이 사용된다.
그래프 탐색이란 - 하나의 정점으로부터 시작하여 차례대로 모든 정점들을 한 번씩 방문하는 것을 말한다.
예를 들어, 특정 도시에서 다른 도시로 이동을 할 수 있는지 탐색하는 것이 될 수 있다.
BFS는 그래프를 탐색시, 너비를 우선 해서 탐색을 하겠다는 전략이다.
즉, 루트 노드에서 시작해서 인접한 노드를 먼저 탐색하는 방법을 말한다.
시작 정점으로부터 가까운 정점을 먼저 방문하고 멀리 떨어져 있는 정점을 나중에 방문하는 순회 방법이다.
깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
사용하는 경우는 보통 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
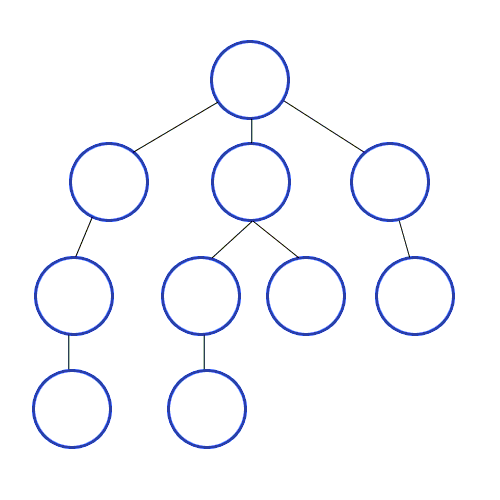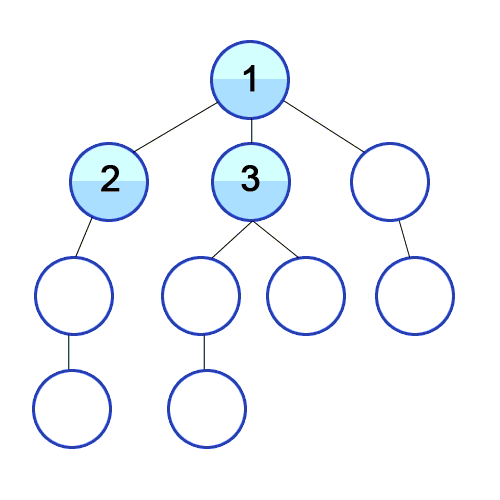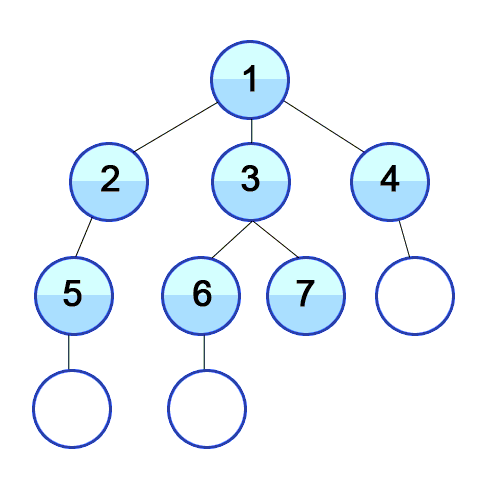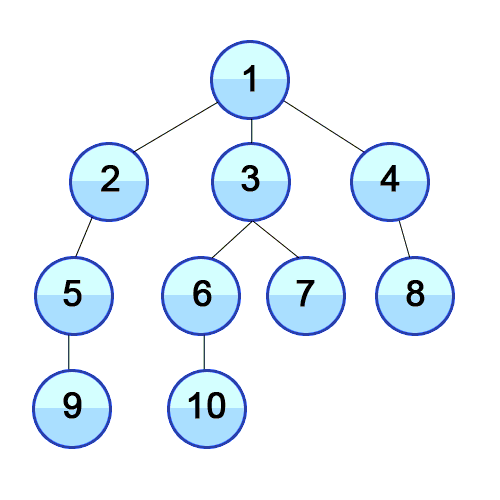
위의 설명을 코드로 나타낸 간단한 의사 코드를 보면 아래와 같을 수 있다.
void search(Node root) {
Queue queue = new Queue();
root.marked = true; // (방문한 노드 체크)
queue.enqueue(root); // 큐에 추가
// 큐가 소진될 때까지 반복한다.
while (!queue.isEmpty()) {
Node r = queue.dequeue(); // 큐에서 노드 추출
r.marked = true; // (방문한 노드 체크)
// 큐에서 꺼낸 노드와 인접한 노드들을 모두 차례로 방문한다.
foreach (Node n in r.adjacent) {
if (n.marked == false) {
queue.enqueue(n); // 큐에 추가
}
}
}
}BFS의 장단점은 아래와 같을 수 있다
- 장점
- 출발 노드로 부터 목표 노드까지의 최단 경로를 보장해 준다.
- 단점
- BFS에 비해 코드 구현이 까다롭다.
- Queue에 노드를 저장하다 보니, 저장공간이 준비되어있어야 한다.
예시 문제
1161 - Maximum Level Sum of a Binary Tree ( 이진트리의 합이 가장 큰 레벨 )
513 - Find Bottom Left Tree Value ( 트리의 가장 밑의 왼쪽 값 찾기 )
429 - N-ary Tree Level Order Traversal ( N-ary 트리의 레벨 순서 순회 )
'Algorithm' 카테고리의 다른 글
| [알고리즘] Backtracking ( 백트래킹, 퇴각 검색 ) (0) | 2021.06.03 |
|---|---|
| [알고리즘] Dynamic Programming ( 동적 계획법 ) (0) | 2021.04.17 |
| [알고리즘] Flood Fill ( Seed Fill ) (0) | 2021.03.27 |
| [알고리즘] DFS ( Depth First Search ) (0) | 2021.03.26 |
| [알고리즘] Union Find (0) | 2020.12.16 |